
Deep Learning Colombia
Que és Deep Learning o Aprendizaje Profundo?
El Aprendizaje Profundo o Deep Learning, es un subcampo de Machine Learning dentro de la Inteligencia Artificial, usa una estructura jerárquica de redes neuronales artificiales, que se construyen de una forma similar a la estructura neuronal del cerebro humano, con los nodos de neuronas conectadas como una tela de araña. Esta arquitectura permite abordar el análisis de datos de forma no lineal.

Al igual que otros algoritmos de aprendizaje, el aprendizaje profundo es una técnica queenseña a los ordenadores a hacer lo que es natural para los humanos: aprender con el ejemplo.
Los vehículos sin conductor, se puede llevar a cabo por la implementación del Deep Learning, que les permite reconocer una señal de tráfico o distinguir un peatón de un farola. Es la clave para el control por voz en dispositivos de consumo como teléfonos, tabletas, televisores y altavoces inteligentes.
Redes Neuronales
A finales del siglo XIX se logró un mayor conocimiento sobre el cerebro humano y su funcionamiento, gracias a los trabajos de Ramón y Cajal en España y Sherrington en Inglaterra. El primero trabajó en la anatomía de las neuronas y el segundo en los puntos de conexión de las mismas o sinapsis.
El tejido nervioso es el más diferenciado del organismo y está constituido por células nerviosas, fibras nerviosas y la neuroglia, que está formada por varias clases de células. La célula nerviosa se denomina neurona, que es la unidad funcional del sistema nervioso. Pueden ser neuronas sensoriales, motoras y de asociación. Se estima que en cada milímetro cúbico del cerebro hay cerca de 50.000 neuronas
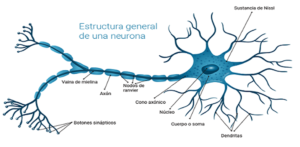
Redes Neuronales Artificiales - ANN
Una Red Neuronal Artificial (RNA) es un modelo matemático inspirado en el comportamiento biológico de las neuronas y en la estructura del cerebro, y que es utilizada para resolver una amplia variedad de problemas. Debido a su flexibilidad, una misma red neuronal es capaz de realizar diversas tareas conviertiéndose pilar del Deep Learning.
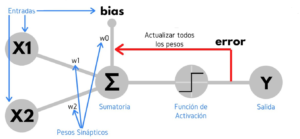
Al igual que sucede en la estructura de un sistema neuronal biológico, los elementos esenciales de proceso de un sistema neuronal artificial son las neuronas. Una neurona artificial es un dispositivo simple de cálculo que genera una única respuesta o salida a partir de un conjunto de datos de entrada.
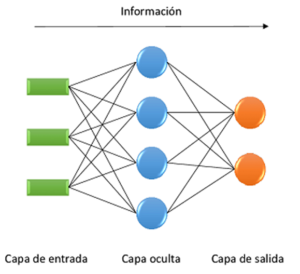
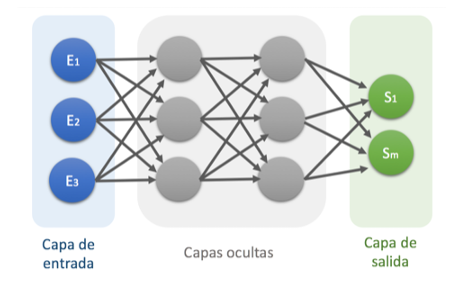
Las neuronas se agrupan dentro de la red formando niveles o capas. Dependiendo de su situación dentro de la red, se distinguen tres tipos de capas: La capa de entrada, que recibe directamente la información procedente del exterior, incorporándola a la red. Las capas ocultas, internas a la red y encargadas del procesamiento de los datos de entrada. La capa de salida, que transfiere información de la red hacia el exterior.
Las RNAs pueden tener varias capas ocultas o no tener ninguna. Los enlaces sinápticos (las flechas llegando o saliendo de una neurona) indican el flujo de la señal a través de la red y tienen asociado un peso sináptico correspondiente. Si la salida de una neurona va dirigida hacia dos o más neuronas de la siguiente capa, cada una de estas últimas recibe la salida neta de la neurona anterior. El número de capas de una RNA es la suma de las capas ocultas más la capa de salida.
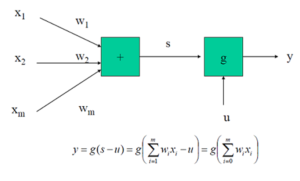
Los elementos que intervienen en una neurona artificial son los siguientes:
- Conjunto de entradas xi
- Pesos sinápticos wi, i = 1,..,m.
- Regla de propagación s que combina las entradas y los pesos sinápticos. Usualmente: s(x1, …, xm, w1,…, wm) = Σ wixi
- Función de activación g, que es función de s y de una constante u (denominado umbral o sesgo), que proporciona la salida y de la neurona.
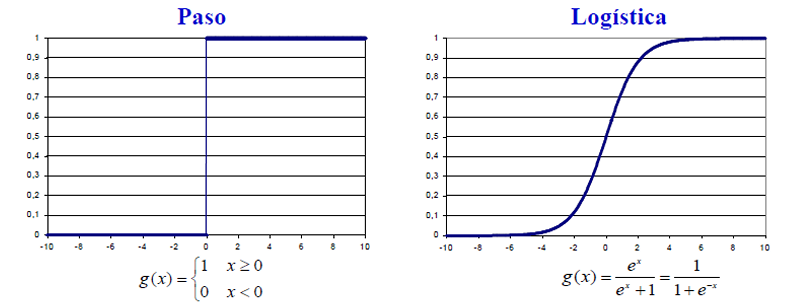
Las funciones de activación mas usales son como se aprecia en las gráficas:
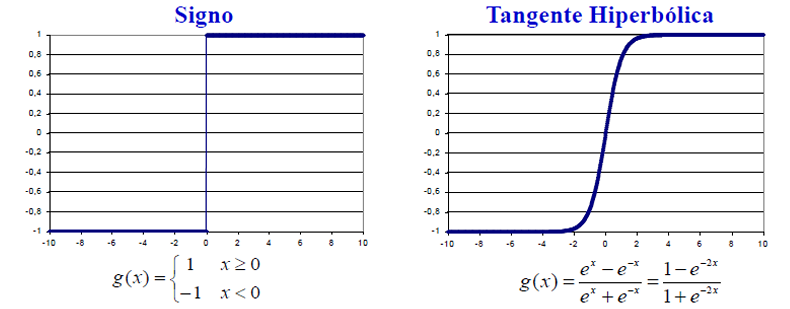
Atendiendo al número de capas en que se organizan las neuronas, las redes neuronales se clasifican en dos grandes grupos:
- Redes monocapa, compuestas por un solo nivel de neuronas que se unen mediante conexiones laterales.
- Redes multicapa, donde las neuronas se disponen en dos o más capas.
Atendiendo al flujo de datos las redes neuronales se clasifican en dos grandes grupos:
- Redes unidireccionales (feedforward): sin ciclos.
- Redes recurrentes o realimentadas (feedback): presentan ciclos
Dada una Red Neuronal Artificial, se llama algoritmo, método o regla de aprendizaje a cualquier procedimiento que permita obtener una asignación de valores para los coeficientes sinápticos (pesos sinápticos y umbral de activación).
Pueden distinguirse distintos tipos de aprendizaje en Redes Neuronales Artificiales:
- Aprendizaje supervisado: Se dispone de un conjunto de ejemplos que contiene tanto los datos de entrada como la salida correcta.
- Aprendizaje no supervisado: Los ejemplos sólo contienen los datos de entrada, pero no la salida.
- Aprendizaje híbrido: Unas capas tienen aprendizaje supervisado y otras no supervisado.
- Aprendizaje por refuerzo: No se dispone de las salidas correctas, aunque se indica a la red en cada caso si ha acertado o no.
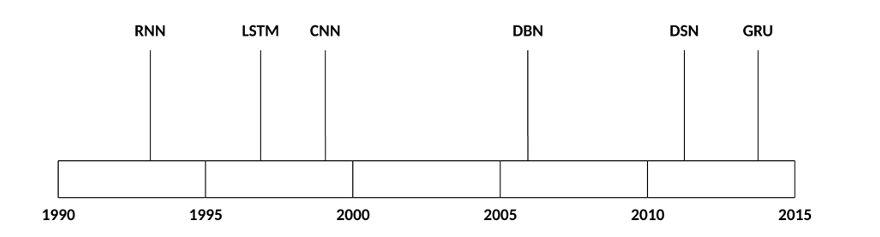
Tipos de Redes Neuronales usadas en Deep Learning
El número de arquitecturas y algoritmos que se utilizan en el aprendizaje profundo es amplio y variado. En este apartado se explorarán algunas de las arquitecturas de aprendizaje profundo que abarcan los últimos 20 años.
Perceptrón Simple
El perceptrón simple es una Red Neuronal Artificial que posee las siguientes características:
- Está formada por dos capas de neuronas.
- Es una red unidireccional hacia adelante.
- Los nodos de la primera capa no realizan ningún cálculo, limitándose a proporcionar los valores de entrada a la red.
- La segunda capa está formada por un solo nodo, que aplica una función de activación paso o signo.
Perceptrón Múltiple
Minsky y Papert (1969) demostraron que el perceptrón simple no puede resolver problemas no lineales. Rumelhart et al. introdujeron en 1986 el perceptrón múltiple (PM), que es una red compuesta por varias capas de neuronas con conexiones hacia adelante (feed-forward) y en la que el aprendizaje es supervisado.
Un perceptrón múltiple puede aproximar relaciones no lineales entre variables de entrada y de salida y es una de las arquitecturas más utilizadas en la resolución de problemas reales por ser aproximador universal, por su fácil uso y aplicabilidad.
El uso del PM es adecuado cuando:
- Se permiten largos tiempos de entrenamiento.
- Se necesitan respuestas muy rápidas ante nuevas instancias.
La arquitectura de un PM es la siguiente :
- Capa de entrada: sólo se encargan de recibir las señales de entrada y propagarlas a la siguiente capa.
- Capa de salida: proporciona al exterior la respuesta de la red para cada patrón de entrada.
- Capas ocultas: Realizan un procesamiento no lineal de los datos recibidos.
Redes Neuronales Recurrentes - RNN
Las RNN son una de las arquitecturas de red fundamentales a partir de las cuales se construyen otras arquitecturas de aprendizaje profundo. La diferencia principal entre una red de múltiples capas típica y una red recurrente es que, en lugar de conexiones completamente avanzadas, una red recurrente puede tener conexiones que se realicen en capas anteriores (o en la misma capa).
Esta retroalimentación permite a las RNN mantener la memoria de entradas pasadas y modelar problemas a tiempo. Las RNN consisten en un rico conjunto de arquitecturas (veremos una topología popular llamada LSTM a continuación).
El elemento diferenciador clave es la retroalimentación dentro de la red, que podría manifestarse desde una capa oculta, la capa de salida o alguna combinación de las mismas. Las RNN se pueden desplegar en el tiempo y entrenarse utilizando el algoritmo de Backpropagation estándar o utilizando una variante del mismo que se denomina propagación hacia atrás en el tiempo (BPTT).
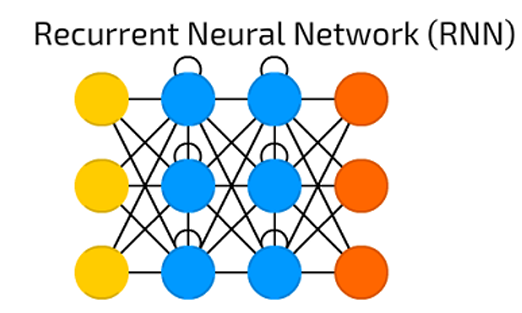
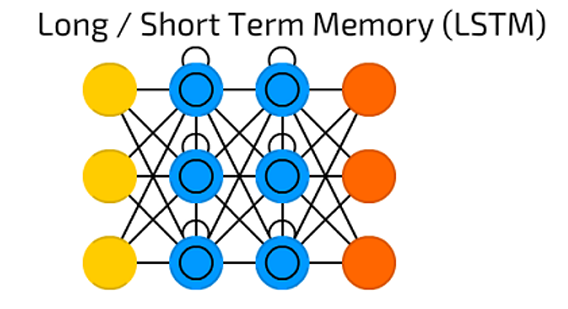
Redes Long/Short Term Memory - LSTM/GRU
Las redes LSTM (Long/Short Term Memory) fueron creadas en 1997 por Hochreiter y Schimdhuber, pero han crecido en popularidad en los últimos años como una arquitectura RNN para varias aplicaciones.
Se encuentran en algunos productos que usamos diariamente como los teléfonos inteligentes. La LSTM se apartó de las típicas arquitecturas de redes neuronales basadas en neuronas y, en cambio, introdujo el concepto de una célula de memoria. La celda de memoria puede retener su valor por un tiempo corto o largo en función de sus entradas, lo que permite a la celda recordar lo que es importante y no solo el último valor procesado.
La celda de memoria LSTM contiene tres puertas que controlan cómo la información f luye dentro o fuera de la celda. La puerta de entrada controla cuándo puede ingresar nueva información a la memoria. La puerta de olvido controla cuando se olvida una parte de la información existente, lo que permite a la celda recordar datos nuevos.
Finalmente, la puerta de salida controla cuando la información que está contenida en la celda se utiliza en la salida de la celda. La celda también contiene pesos, que controlan cada puerta.
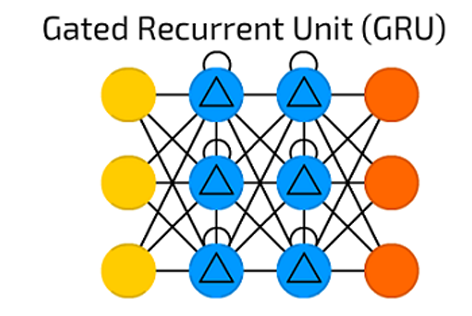
En 2014, se introdujo una simplificación de la LSTM llamada unidad recurrente cerrada (Gatod Recurrent Unit o abreviadamente GRU) . Este modelo tiene solo dos puertas, eliminando la puerta de salida presente en el modelo LSTM.
Para muchas aplicaciones, el GRU tiene un rendimiento similar al LSTM, pero, al ser más simple, involucra menos pesos y permite una ejecución más rápida. La GRU incluye dos puertas: una puerta de actualización y una puerta de restablecimiento. La puerta de actualización indica la cantidad de contenido de la celda anterior a mantener. La puerta de reinicio define cómo incorporar la nueva entrada al contenido de la celda anterior.
Una GRU puede modelar un RNN estándar simplemente configurando la puerta de restablecimiento en 1 y la puerta de actualización en 0. La GRU es más simple que el LSTM, puede entrenarse más rápidamente y puede ser más eficiente en su ejecución. Sin embargo, el LSTM puede ser más expresivo y, con más datos, puede conducir a mejores resultados.
Redes Neuronales Convolucioneales - CNN
Una CNN es una red neuronal multicapa inspirada biológicamente en la corteza visual animal. La arquitectura es particularmente útil en aplicaciones de procesamiento de imágenes.
La primera CNN fue creada por Yann LeCun; en ese momento, la arquitectura se centraba en el reconocimiento de caracteres manuscritos, como la interpretación de códigos postales. Como una red profunda, las primeras capas reconocen características (como los bordes), y las capas posteriores recombinan estas características en atributos de entrada de nivel superior.
La principal ventaja de este tipo de redes es que cada parte de la red es entrenada para realizar una tarea; esto reduce significativamente el número de capas ocultas, por lo que el entrenamiento es más rápido. Además, es invariante por traslación de los patrones a identificar.
Las redes neuronales convolucionales son muy potentes para todo lo que tiene que ver con el análisis de imágenes, debido a que son capaces de detectar las características simples como ,por ejemplo, bordes, líneas, etc., y componer en estructuras más complejas hasta detectar lo que se busca.
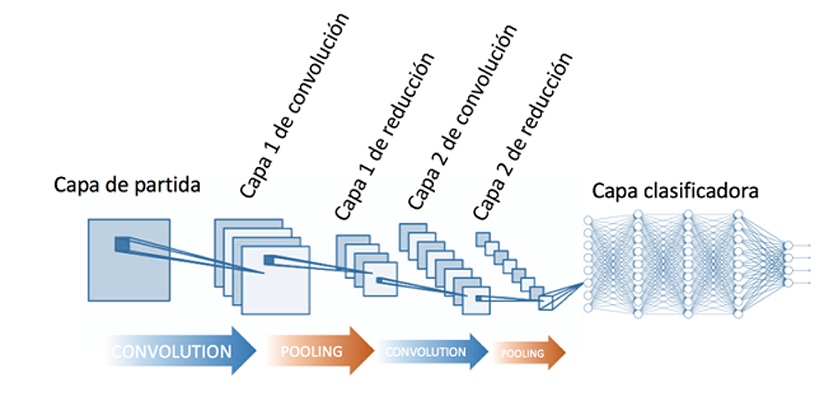
Una red neuronal convolucional es una red multicapa que consta de capas convolucionales y de reducción alternadas, y, finalmente, tiene capas de conexión total como una red perceptrón multicapa.
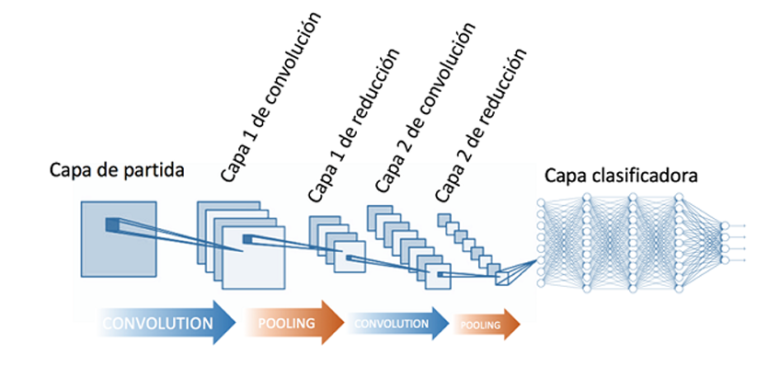
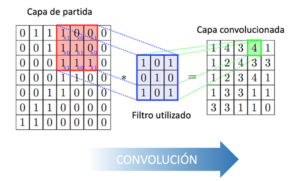
En la convolución se realizan operaciones de productos y sumas entre la capa de partida y los n filtros (o núcleos) que genera un mapa de características. Las características extraídas corresponden a cada posible ubicación del filtro en la imagen original. La ventaja reside en que la misma neurona sirve para extraer la misma característica en cualquier parte de la entrada; con esto se consigue reducir el número de conexiones y el número de parámetros a entrenar en comparación con una red multicapa de conexión total.
Después de la convolución se aplica a los mapas de características una función de activación. La función de activación recomendada es sigmoide ReLU (Rectified Linear Unit), seleccionando una tasa de aprendizaje adecuada monitorizando la fracción de neuronas muertas, también se puede podría probar con Leaky ReLu o Maxout, pero nunca utilizar la función sigmoide logística.
En la reducción (pooling) se disminuye la cantidad de parámetros al quedarse con las características más comunes. La forma de reducir parámetros se realiza mediante la extracción de medidas estadísticas como el promedio o el máximo de una región fija del mapa de características; al reducir características el método pierde precisión aunque mejora su compatibilidad.
Al final de las capas convolucional y de reducción, se suelen utilizar capas completamente conectadas en la que cada pixel se considera como una neurona separada al igual que en un perceptrón multicapa. La última capa de esta red es una capa clasificadora que tendrá tantas neuronas como número de clases a predecir haya.
Redes de Creencias Profundas - DBN
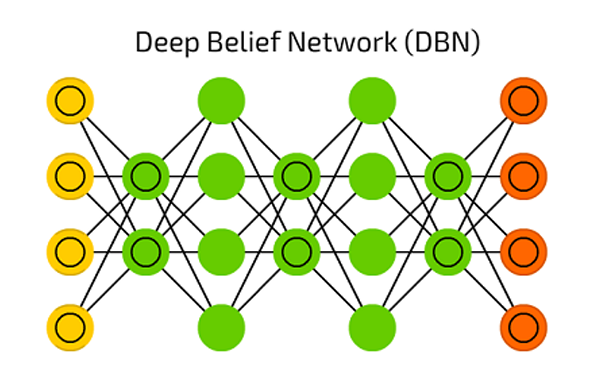
La DBN (Deep Belief Network) es una arquitectura de red típica pero incluye un algoritmo de entrenamiento novedoso. La DBN es una red multicapa (generalmente profunda, que incluye muchas capas ocultas) en la que cada par de capas conectadas es una máquina de Boltzmann restringida (RBM) que es un tipo de red neuronal recurrente estocástica.
Las máquinas de Boltzmann pueden considerarse como la contrapartida estocástica y generativa de las redes de Hopfield. Fueron de los primeros tipos de redes neuronales capaces de aprender mediante representaciones internas, son capaces de representar y (con tiempo suficiente) resolver complicados problemas combinatorios.
En las DBN, la capa de entrada representa las entradas sensoriales en bruto, y cada capa oculta aprende representaciones abstractas de esta entrada. La capa de salida, que se trata de manera algo diferente a las otras capas, implementa la clasificación de red. El aprendizaje se realiza en dos pasos: entrenamiento previo sin supervisión y ajuste fino supervisado
Aplicaciones Deep Learning - Aprendizaje Profundo
RNA Multicapa
Pueden resolver problemas supervisados y no supervisados de clasificación y regresión.
RNN
Reconocimiento de voz, reconocimiento de escritura a mano.
LSTM
Compresión de texto en lenguaje natural, reconocimiento de escritura a mano, reconocimiento de voz, reconocimiento de gestos, pronósticos de series de tiempo precios acciones
CNN
Reconocimiento de imágenes, análisis de video, procesamiento de lenguaje natura
DNB
Reconocimiento de imágenes, recuperación de información, comprensión del lenguaje natural, predicción de fallas, etc
GRU
Recuperación de información, reconocimiento continuo de voz.
¿Cómo mantenerse actualizado en el campo de Deep Learning?
El campo del Deep Learning se mueve muy rápidamente, con varios papers que se publican por mes; por tal motivo, mantenerse actualizado con las últimas tendencias del campo puede ser bastante complicado. Algunos consejos pueden ser:
Estarse atento a las publicaciones en arxiv, especialmente a la sección de machine learning. La mayoría de los papers más relevantes, los vamos a poder encontrar en esa plataforma.
Seguir el blog de keras en el cual podemos encontrar como implementar varios modelos utilizando esta genial librería.
Seguir el blog de openai en dónde detallan las investigaciones que van realizando, especialmente trabajando con GANs.
Seguir el blog de Google research; en dónde se viene haciendo bastante foco en los modelos de Deep Learning.