Para aplicar el machine learning a la predicción de propiedades, primero debemos contar con un conjunto de datos que incluya información relevante sobre las propiedades que queremos predecir. Por ejemplo, si queremos predecir la dureza de un material, nuestro conjunto de datos podría incluir información sobre la composición química, la estructura cristalina, la densidad y otros factores que se sabe que influyen en la dureza. Una vez que tenemos un conjunto de datos de entrenamiento, podemos utilizar varios algoritmos de aprendizaje automático para crear modelos que puedan predecir la propiedad en cuestión.
Uno de los algoritmos de aprendizaje automático más utilizados para la predicción de propiedades es la regresión lineal. Este algoritmo busca encontrar una relación lineal entre las características de entrada (en nuestro ejemplo, la composición química, la estructura cristalina, etc.) y la propiedad de salida (en nuestro ejemplo, la dureza). En otras palabras, la regresión lineal trata de encontrar la mejor línea recta que se ajuste a los datos de entrenamiento.
Otro algoritmo de aprendizaje automático que se utiliza comúnmente para la predicción de propiedades es el árbol de decisión. Este algoritmo crea un árbol de decisiones que se basa en las características de entrada para predecir la propiedad de salida. Cada nodo del árbol representa una característica de entrada, y las ramas del árbol representan las diferentes posibles valores de esa característica. El algoritmo utiliza los datos de entrenamiento para construir el árbol de decisiones de tal manera que minimice el error de predicción.
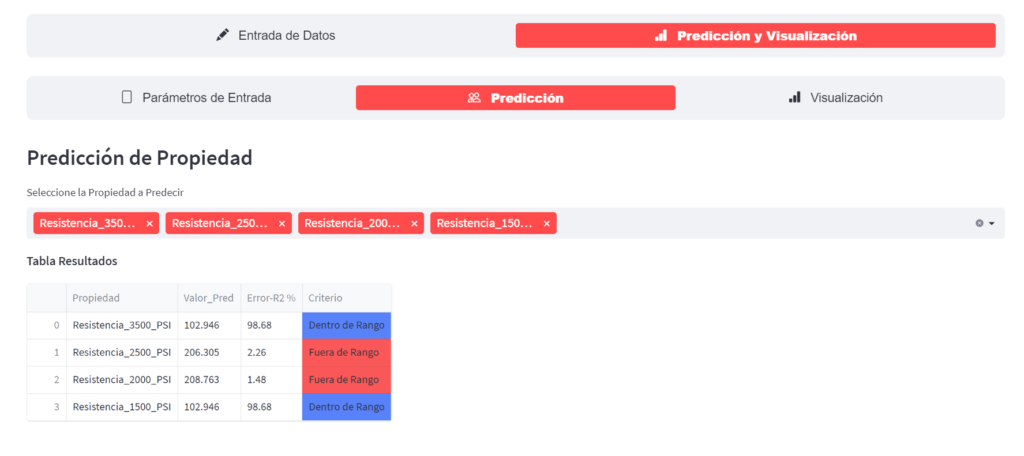
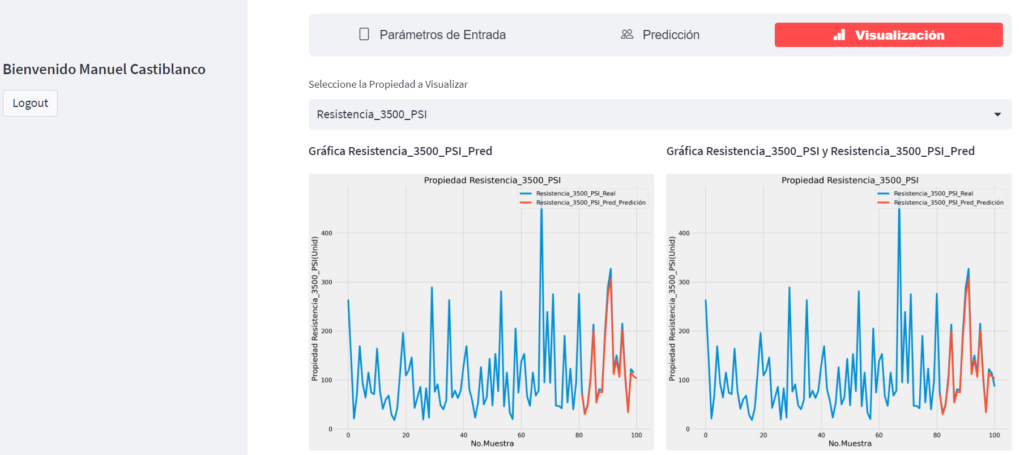
Una vez que se ha entrenado un modelo de aprendizaje automático, se puede utilizar para hacer predicciones sobre nuevos datos. Por ejemplo, si queremos predecir la dureza de un material desconocido, podríamos proporcionar la información sobre su composición química, estructura cristalina, etc. al modelo y este nos proporcionaría una predicción de la dureza.
Es importante tener en cuenta que el proceso de entrenamiento de un modelo de aprendizaje automático puede ser muy intensivo en términos de recursos computacionales, especialmente si el conjunto de datos de entrenamiento es muy grande o si se están utilizando algoritmos más complejos. Además, los modelos de aprendizaje automático pueden ser susceptibles a sobreajuste o «overfitting», que ocurre cuando el modelo se ajusta demasiado a los datos de entrenamiento y no es capaz de generalizar bien a nuevos datos.
Para evitar el sobreajuste, es importante utilizar técnicas como la validación cruzada y el conjunto de validación para evaluar el rendimiento del modelo en datos que no se han utilizado para el entrenamiento. Además, se pueden utilizar técnicas como la regularización para reducir la complejidad del modelo y evitar el sobreajuste.