En 1959, el científico de la IBM Arthur Samuel escribió un programa para jugar damas, para mejorarlo hizo que el programa jugara consigo mismo miles de veces, el programa era capaz de mejorar su rendimiento a través de la experiencia, el programa aprendió y nació el Machine Learning y desde allí el desarrollo de sus aplicaciones.
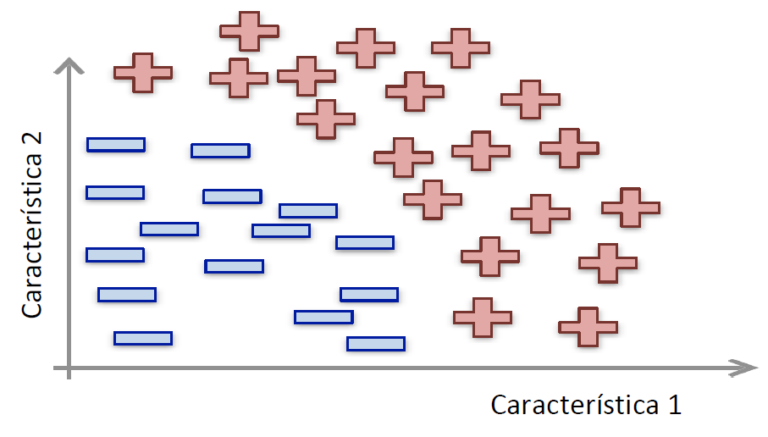
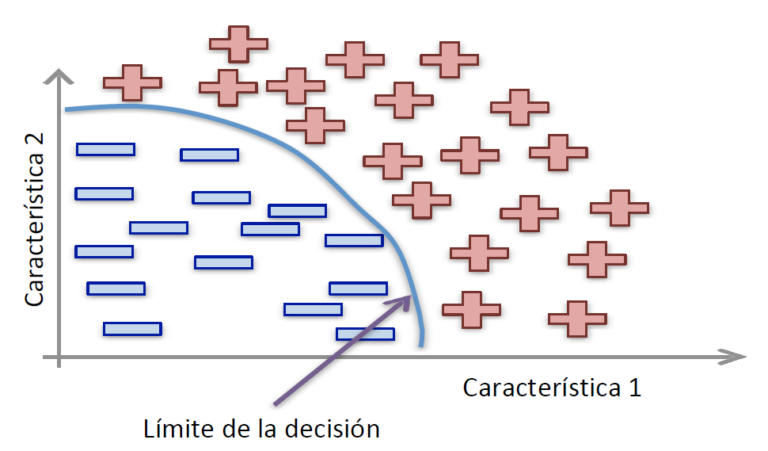
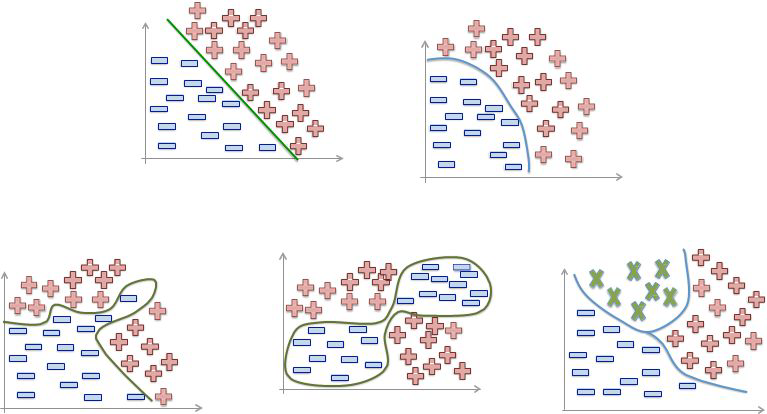
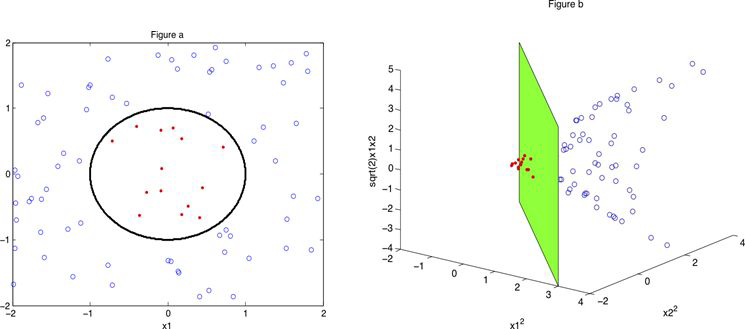
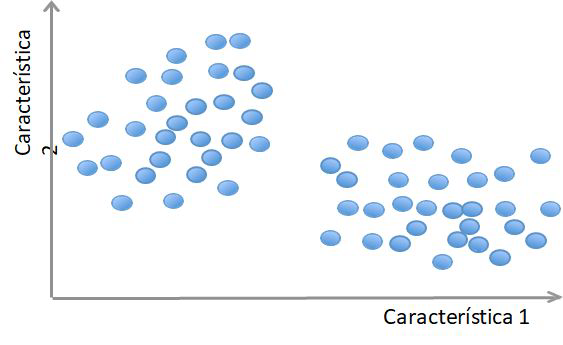
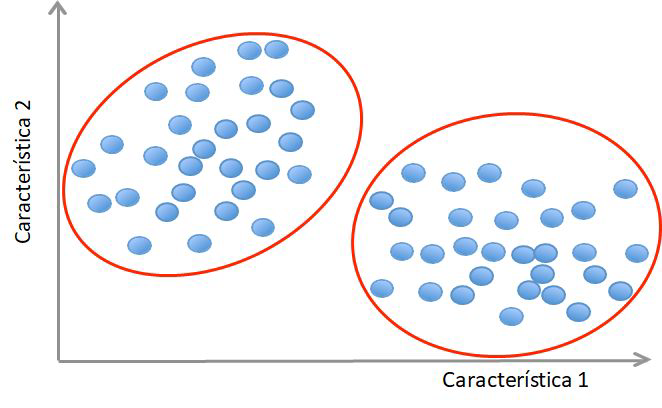
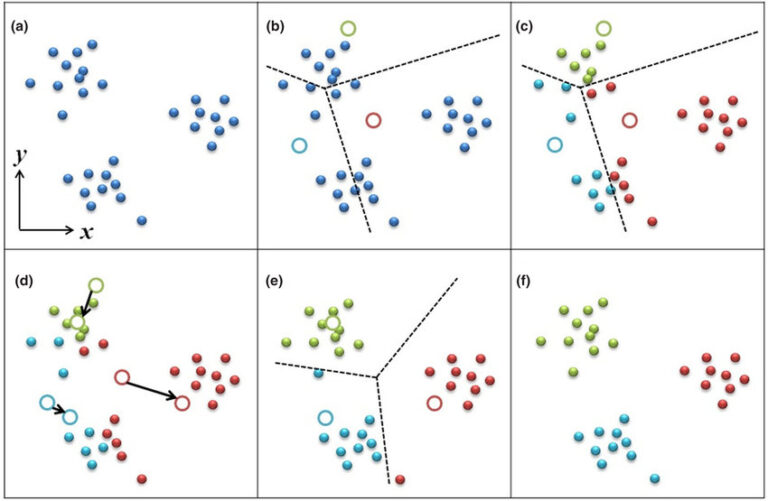
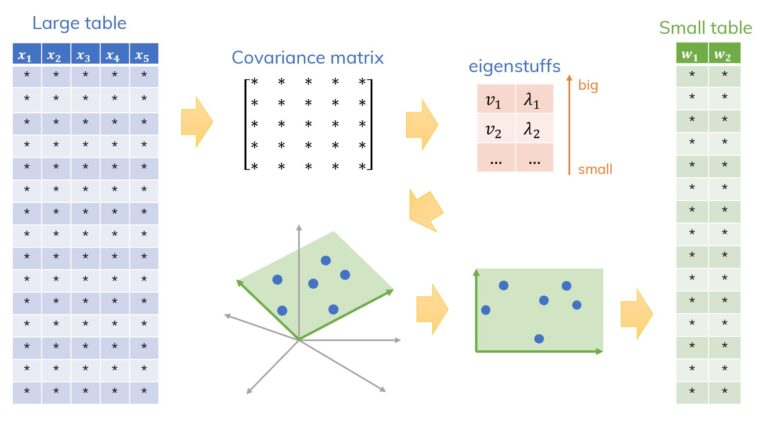
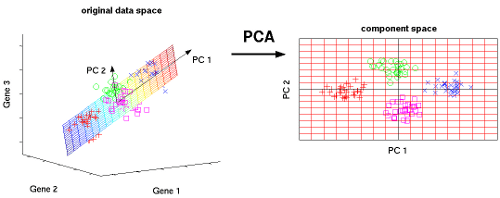
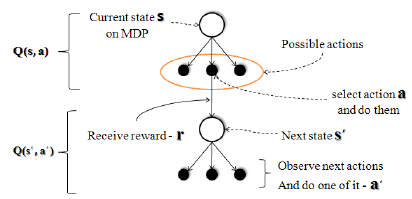
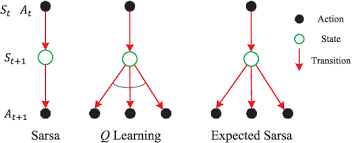
La Inteligencia Artificial tiente como campo el Machine Learning o también conocido como Aprendizaje Automático, donde las máquinas pueden «aprender» de sí mismas, sin ser explícitamente programadas por los seres humanos. Analizando datos pasados llamados «datos de entrenamiento», el modelo de Aprendizaje Automático forma patrones y usa estos patrones para aprender y hacer predicciones futuras.